In today's development world we are exposed to both SQL and No-SQL database operations. At some point we may need to map a JSON data to SQL table . Here is an article to parse JSON in SQL. Let's start.
Suppose front-end /client sends JSON data in string format. Define a variable to store the JSON string as below.
DECLARE @json nvarchar(max) ;
//input from client
set @json = N'[{ \"mid\": \"/m/01dvt1\", \"description\": \"Joint\", \"score\": 0.975906968,
\"topicality\": 0.975906968 }, { \"mid\": \"/m/0dzf4\", \"description\": \"Arm\", \"score\": 0.9426941, \"topicality\": 0.9426941 },
{ \"mid\": \"/m/01ssh5\", \"description\": \"Shoulder\", \"score\": 0.936277151, \"topicality\": 0.936277151 },
{ \"mid\": \"/m/035r7c\", \"description\": \"Leg\", \"score\": 0.925112, \"topicality\": 0.925112 },
{ \"mid\": \"/m/01d40f\", \"description\": \"Dress\", \"score\": 0.920576453, \"topicality\": 0.920576453 },
{ \"mid\": \"/m/02p0tk3\", \"description\": \"Human body\", \"score\": 0.8836405, \"topicality\": 0.8836405 },
{ \"mid\": \"/m/062581\", \"description\": \"Sleeve\", \"score\": 0.8722252, \"topicality\": 0.8722252 },
{ \"mid\": \"/m/019swr\", \"description\": \"Knee\", \"score\": 0.8650081, \"topicality\": 0.8650081 },
{ \"mid\": \"/m/01j04m\", \"description\": \"Thigh\", \"score\": 0.858148634, \"topicality\": 0.858148634 },
{ \"mid\": \"/m/01vm1p\", \"description\": \"Elbow\", \"score\": 0.834722638, \"topicality\": 0.834722638 }]';
This is a JSON data in string format (equivalent to JSON.stringify() in JavaScript). Before proceeding to map data, first we should generate a valid JSON object out of the string input. We can do that by replacing "/" and "\" with space. Here is the code.
set @json = REPLACE(@json,'\','');
set @json = REPLACE(@json,'/','');
SQL has in-built method "OPENJSON" to convert a JSON object to row and column format. Let's see the output.
select * from OPENJSON ( @json ) ;
Output
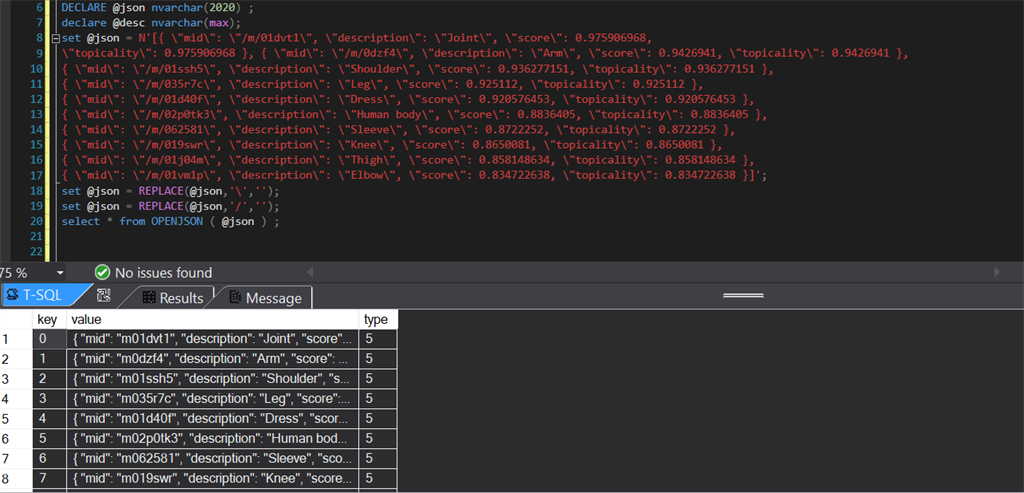
Here "type" refers to data type of JSON data. For more info about OPENJSON, here is a link MSDN.
Now, we have to parse value column into SQL column. We can do so by using below query.
select * FROM
OPENJSON ( @json )
WITH (
mid varchar(10) '$.mid',
description varchar(max) '$.description',
score nvarchar(20) '$.score',
topicality float '$.topicality'
)
select @desc as Description
Here $.mid,$.description, $.score and $.topicality are JSON properties. Based on your JSON property name , you need to replace it.
Output
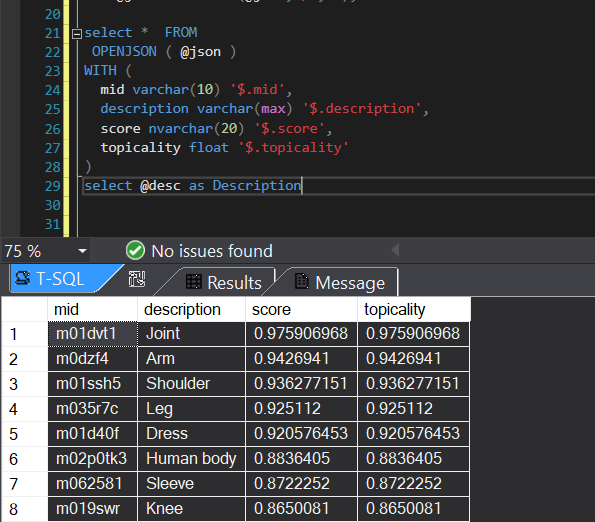
We can copy these records to a SQL table as below.
insert into jsondata (mid,description,score,topicality)
select mid,description,score,topicality
FROM
OPENJSON ( @json )
WITH (
mid varchar(10) '$.mid',
description varchar(max) '$.description',
score nvarchar(20) '$.score',
topicality float '$.topicality'
);
select * from jsondata;
Here, i am trying to insert JSON data to an existing SQL table records.
Output

We can map No-SQL data to a SQL data table using SQL predefined method , that is "OPENJSON". I hope this article is helpful for you. Thanks you for spending time to read it. I am always open for any input or suggestion. Thank you!
HostForLIFEASP.NET SQL Server 2019 Hosting
