A number of noteworthy T-SQL improvements included in SQL Server 2022 simplify data handling, particularly when utilizing analytics, window functions, and sliding aggregations. These new features can be used by database administrators, data engineers, and SQL developers to streamline complicated data operations, enhance readability, and maximize query performance.
Key Enhancements in SQL Server 2022 Window Functions
- OVER with ORDER BY for Aggregate Functions: Allows running and sliding aggregations.
- Sliding Aggregations at Account Level: Maximize window rows and apply at a granular level.
- WINDOW Clause: Reduces code duplication.
- IGNORE NULLS: Optimizes data analysis for first and last values.
- IGNORE VALUES for NULLs in Aggregations: Adds flexibility in handling NULL data points.
We will use the table below for our examples.CREATE TABLE dbo.AccountTransactions (
AccountID INT,
TransactionDate DATE,
Amount DECIMAL(10, 2)
);
INSERT INTO dbo.AccountTransactions (AccountID, TransactionDate, Amount)
VALUES
(1, '2023-01-01', 100.00),
(1, '2023-01-02', 150.00),
(1, '2023-01-03', 200.00),
(1, '2023-01-04', NULL),
(1, '2023-01-05', 300.00),
(2, '2023-01-01', 500.00),
(2, '2023-01-02', 700.00),
(2, '2023-01-03', NULL),
(2, '2023-01-04', 800.00),
(2, '2023-01-05', 900.00);
1. Using OVER with ORDER BY for Aggregate Functions
In SQL Server 2012, Microsoft introduced the ability to use OVER with ORDER BY for aggregate functions, which allows for running and sliding aggregations. This feature lets you compute cumulative totals, moving averages, and other metrics across an ordered dataset without needing a self-join or correlated subquery.Example. Running Total of Transactions by Account
The following query calculates a running total of transaction amounts per AccountID, ordered by TransactionDate.
SELECT
AccountID,
TransactionDate,
Amount,
SUM(Amount) OVER (PARTITION BY AccountID ORDER BY TransactionDate) AS RunningTotal
FROM dbo.AccountTransactions
ORDER BY AccountID, TransactionDate;
/*
The SUM function is paired with OVER (PARTITION BY AccountID ORDER BY TransactionDate). For each row, it calculates a running total of the Amount column by partitioning the data by AccountID and ordering it by TransactionDate.
*/
Output
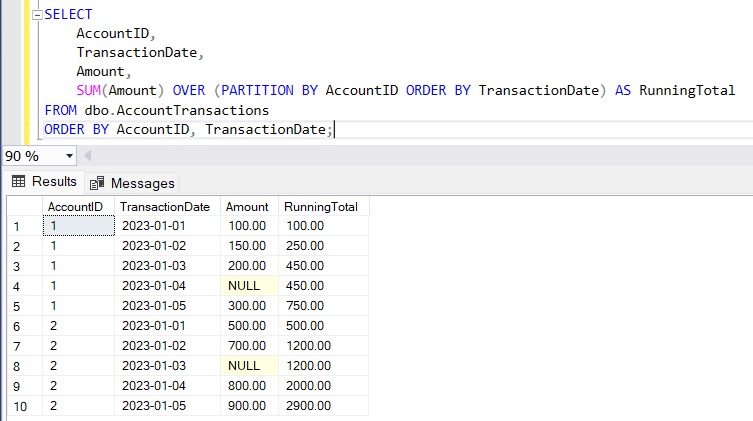
Use Case: Running totals are helpful for calculating cumulative spending per account, which is common in financial reporting or customer analytics.
2. Sliding Aggregations with a Limit on Rows per Window
Sliding aggregations are a specific type of windowed calculation where only a fixed number of preceding or following rows are considered. In SQL Server 2022, this can be particularly useful for rolling averages or sums over a specified window of rows.
Example. Three-Row Sliding Sum
In this example, we calculate a sliding sum of the amount for each of the three most recent transactions of each AccountID.
SELECT
AccountID,
TransactionDate,
Amount,
SUM(Amount) OVER (PARTITION BY AccountID ORDER BY TransactionDate ROWS 2 PRECEDING) AS SlidingSum
FROM dbo.AccountTransactions
ORDER BY AccountID, TransactionDate;
/*
The ROWS 2 PRECEDING clause limits the window to the current row and the previous two rows. This is a rolling three-row sum, which helps in understanding recent trends in transaction amounts.
*/
Output
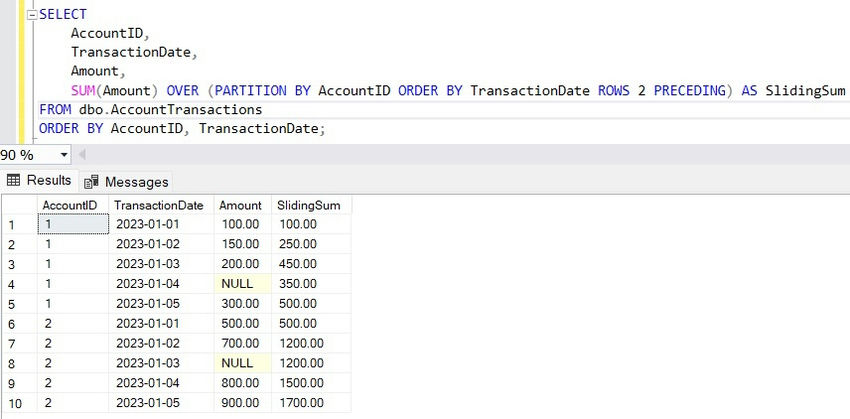
Use Case. Financial analysts might use a sliding aggregation to calculate moving averages, which is useful for smoothing out trends over a defined period
3. Using the WINDOW Clause to Eliminate Code Duplication
The WINDOW clause, introduced in SQL Server 2022, allows you to define a window frame once and reference it multiple times. This feature helps reduce code duplication and improves readability, especially in queries with multiple windowed calculations.
Example. Defining and Using a Window
Here, we define a window once using the WINDOW clause and reference it for both the running total and the sliding sum.
SELECT
AccountID,
TransactionDate,
Amount,
SUM(Amount) OVER w AS RunningTotal,
AVG(Amount) OVER w AS RollingAverage
FROM dbo.AccountTransactions
WINDOW w AS (PARTITION BY AccountID ORDER BY TransactionDate ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
ORDER BY AccountID, TransactionDate;
/*
The WINDOW clause defines a reusable window called w, which can then be applied to different aggregates, reducing code repetition and making modifications easier.
*/
Output
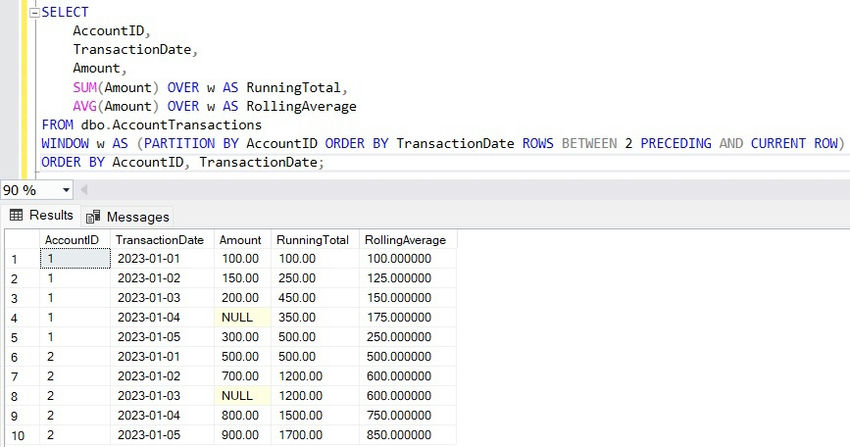
Use Case. The WINDOW clause is particularly valuable in analytics queries where multiple window functions need to use the same partition and order criteria.
4. Using IGNORE NULLS in FIRST_VALUE and LAST_VALUE Functions
The IGNORE NULLS option, introduced in SQL Server 2022, allows window functions like FIRST_VALUE and LAST_VALUE to skip NULL values, making it easier to retrieve non-null values in sequences with missing data.
Example. Getting the Last Non-NULL Value per Account
In this example, we use LAST_VALUE with IGNORE NULLS to fetch the most recent non-null transaction amount for each account.
SELECT
AccountID,
TransactionDate,
Amount,
LAST_VALUE(Amount) IGNORE NULLS OVER (PARTITION BY AccountID ORDER BY TransactionDate) AS LastNonNullAmount
FROM dbo.AccountTransactions
ORDER BY AccountID, TransactionDate;
/*
Without IGNORE NULLS, the LAST_VALUE function would return a NULL value if the last row in the partition contained NULL. With IGNORE NULLS, SQL Server skips over the NULL values and returns the most recent non-null value instead.
*/
Output
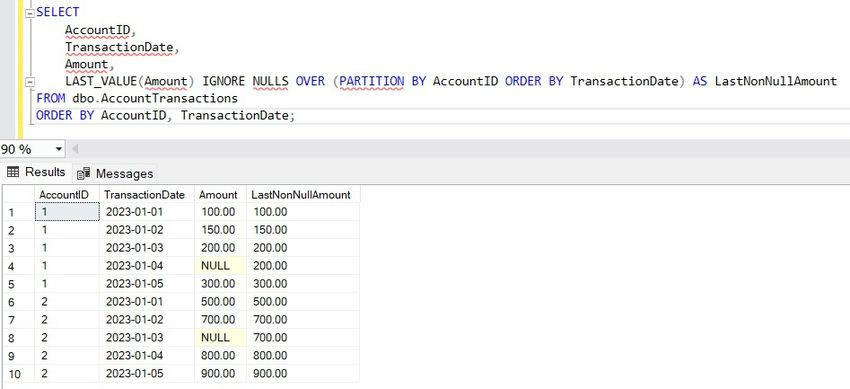
Use Case. This is particularly useful for handling incomplete or intermittent data, such as filling in missing stock prices, temperature readings, or any sequential time-based metric.
5. Handling NULLs with the IGNORE NULLS Option for Aggregations
SQL Server 2022's IGNORE NULLS option can also be applied to functions like SUM and AVG, making it easier to handle datasets with missing values without affecting calculations.
Example. Average Transaction Amount Ignoring NULLs
The following query calculates the average transaction amount for each account while ignoring NULL values.
SELECT
AccountID,
TransactionDate,
Amount,
SUM(Amount) OVER (PARTITION BY AccountID ORDER BY TransactionDate ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) /
NULLIF(COUNT(Amount) OVER (PARTITION BY AccountID ORDER BY TransactionDate ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW), 0)
AS AverageAmount
FROM dbo.AccountTransactions
ORDER BY AccountID, TransactionDate;
/*
With IGNORE NULLS, the calculation ignores rows where Amount is NULL, providing a more accurate average.
*/
Output
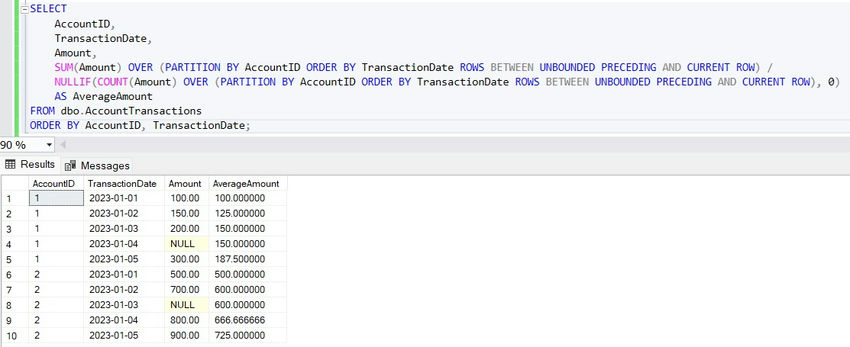
Use Case: NULL values are common in datasets, and having the ability to ignore them directly in aggregation functions simplifies code and improves result accuracy.
Conclusion
SQL Server 2022 brings powerful enhancements to window functions, making them more flexible and capable of handling real-world scenarios in SQL development. From running totals and sliding windows to null handling with IGNORE NULLS, these features improve the clarity, efficiency, and precision of windowed calculations. By leveraging these new tools, SQL developers, data engineers, and DBAs can build more expressive and performant SQL queries, making SQL Server 2022 a strong choice for data-intensive applications.
HostForLIFEASP.NET SQL Server 2022 Hosting
