Table-valued parameters are similar to parameter arrays in that they eliminate the need to build a temporary table or employ numerous parameters by enabling the sending of multiple rows of data to a Transact-SQL statement or routine, such as a stored procedure or function. This article explains how to use a Microsoft SQL Server table-valued argument in a stored procedure.
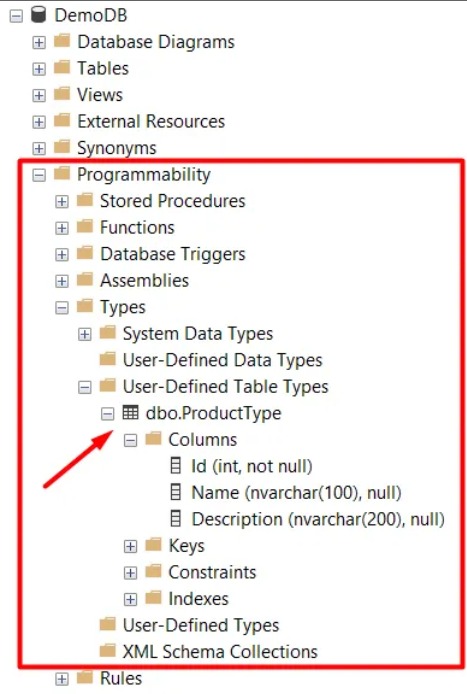
User-Defined Table Types are tables designed to hold temporary data and are used to declare table-valued parameters. Thus, you can make a Type Table and send it as a parameter for a process that requires, for instance, to receive a list of items. For demonstration purposes, I created a table of products that will be used in the following examples. This is the structure of the Products table.
CREATE TABLE Products (
Id INT NOT NULL,
Name NVARCHAR(100) NULL,
Description NVARCHAR(200) NULL,
CreatedDate DATETIME2 NOT NULL CONSTRAINT [DF_Products_CreatedDate] DEFAULT GETUTCDATE(),
CreatedBy NVARCHAR(150) NOT NULL,
CONSTRAINT PK_Product PRIMARY KEY(Id)
);
Adding Just One Product
Imagine a situation in which a user opens your app and needs to register just one item. And to do that, a process for adding this product to the database must exist. You must first develop a procedure to add a single product to the products database in order to accomplish that. The ID, Name, Description, and the user who created the product should be sent as parameters to this procedure.
CREATE PROCEDURE InsertProduct (
@Id INT,
@Name NVARCHAR(100),
@Description NVARCHAR(200),
@User NVARCHAR(150)
)
AS
BEGIN
INSERT INTO Products (
Id,
Name,
Description,
CreatedBy
)
VALUES (
@Id,
@Name,
@Description,
@User
);
END
For testing this procedure, we can run some scripts adding aBEGIN TRANSACTIONwith aROLLBACKin the end (this is useful when testing to avoid needing to delete/change/revert the data on each test that is made), and inside of that, we can execute the statements to insert the products.
BEGIN TRANSACTION
SELECT * FROM Products;
EXEC InsertProduct 1, 'Galaxy S22', 'Smartphone Samsung Galaxy S22', 'Henrique';
EXEC InsertProduct 2, 'iPhone 14 Pro', 'Smartphone Apple iPhone 14 Pro', 'Henrique';
EXEC InsertProduct 3, 'iPhone 13 Pro', 'Smartphone Apple iPhone 13 Pro', 'Henrique';
SELECT * FROM Products;
ROLLBACK
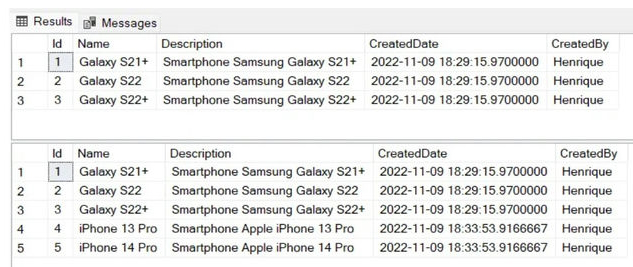
On line 1, there is the BEGIN transaction statement, and this is to allow us to revert the changes at the end of the execution.
On line 3, we run aSELECTquery to check the data in the products table.
On lines 5 up to 7, we run the InsertProductprocedure to insert the products. Note that in order to insert three products, we needed to execute the procedure three times, once for each product.
On line 9, we run a new select query to check the data in the products table.
On line 11, there is the rollback statement, to revert the changes that were made.
This is the result.
Adding a Large Number of Products
Now imagine a situation where you receive a list of products to add to the product table, rather than just one product. In this instance, a Table Type parameter—which functions as a sort of array of products—should be included in the code. The properties that are listed in the products table should also be included in the type table's columns. For instance, the type table will include the columns Name and Description.
CREATE TYPE ProductType AS TABLE (
Id INT NOT NULL,
Name NVARCHAR(100) NULL,
Description NVARCHAR(200) NULL,
PRIMARY KEY(Id)
);
Once the Type Table is created, it’s possible to see it here.
The type table and the user entering the records will be the two arguments for the new method we'll be creating, InsertProducts (plural). The Insert Products process is as follows.
CREATE PROCEDURE InsertProducts (
@Products ProductType READONLY,
@User NVARCHAR(150)
)
AS
BEGIN
INSERT INTO Products (
Id,
Name,
Description,
CreatedBy
)
SELECT
prd.Id,
prd.Name,
prd.Description,
@User
FROM @Products prd
END
- On line 2, there is the parameter@Productsof typeProductType, and it must have theREADONLYkeyword.
- On line 3, there is the parameter@CreatedByof typeNVARCHAR, which is for saving the name of the user who runs the procedure to insert products. Note: this second parameter is here only to demonstrate that even when a procedure has a type table as a parameter, is still possible to use more parameters of different types — in case you need to get the user who executed the SQL script, you can use theSYSTEM_USERin the SQL Script, instead of receiving the user as a parameter.
- On line 7, the INSERT statement begins.
- On line 13, there is the select query, which will read the data from the table type that was received as a parameter (@Products), and it will use the data to insert it into the product table.
Let’s test the procedure now. For that, let’s use the TRANSACTION with aROLLBACKin the end, as we did before, and for testing, we will add some data into the type table and execute the procedure by sending this type table as a parameter.
BEGIN TRANSACTION
SELECT * FROM Products;
DECLARE @Products ProductType;
INSERT INTO @Products
SELECT 1, 'Galaxy S22+', 'Smartphone Samsung Galaxy S22+'
UNION ALL
SELECT 2, 'iPhone 14 Pro', 'Smartphone Apple iPhone 14 Pro'
UNION ALL
SELECT 3, 'iPhone 13 Pro', 'Smartphone Apple iPhone 13 Pro';
EXEC InsertProducts @Products, 'Henrique';
SELECT * FROM Products;
ROLLBACK
- On line 1, a new transaction is started.
- On line 3, we first run select to check the data we have in the product table before running the procedure.
- On line 5, the variable of typeProductTypeis declared.
- On lines 7 up to 12, three records are inserted into the@Productsvariable.
- On line 14, the procedure to insert products is executed and receives as parameters the Type table variable (@Products) and a user ('Henrique').
- On line 16, a new selection, the Productstable is executed, and the three records are expected to be inserted into the table.
- On line 18, a rollback is executed to revert the changes.
This is the result.
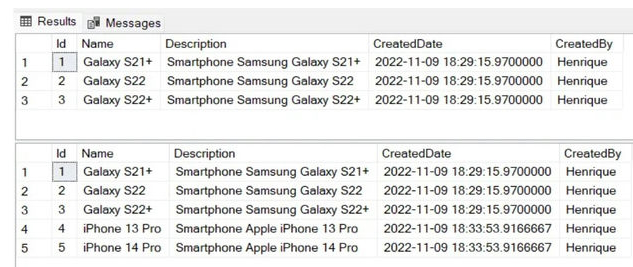
Since this is a new table, it is to be expected that the initial select query returned no results. The three products were added to the product table using the second select query, which was run subsequent to the insert function. For the scenarios in which the product table contains records, let's run another test. Let's add additional data to the table to support that.
INSERT INTO Products (Id, Name, Description, CreatedBy)
VALUES (1, 'Galaxy S21+', 'Smartphone Samsung Galaxy S21+', 'Henrique'),
(2, 'Galaxy S22', 'Smartphone Samsung Galaxy S22', 'Henrique'),
(3, 'Galaxy S22+', 'Smartphone Samsung Galaxy S22+', 'Henrique');
Now, let’s do another test, adding new records using the InsertProductsprocedure.
BEGIN TRANSACTION
SELECT * FROM Products;
DECLARE @Products ProductType;
INSERT INTO @Products
SELECT 4, 'iPhone 13 Pro', 'Smartphone Apple iPhone 13 Pro'
UNION ALL
SELECT 5, 'iPhone 14 Pro', 'Smartphone Apple iPhone 14 Pro';
EXEC InsertProducts @Products, 'Henrique';
SELECT * FROM Products;
ROLLBACK
- On line 3, the first SELECT will return the records that were previously added to the products table.
- On line 5, the variable of typeProductTypeis declared.
- On lines 7 up to 10, two products are added to theProductTypetable, which will be used as a parameter to the procedure.
- On line 12, the procedureInsertProductsis executed.
- On line 14, a second selects executed, to return the products.
This is the result.
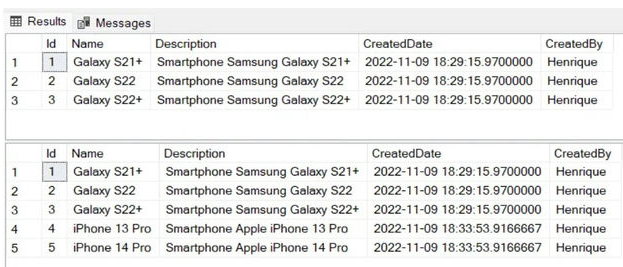
The new records with Ids 4 and 5 were added to the product table as anticipated.
In summary
It is feasible to build a stored method or function that requires a list of data as a parameter by declaring User-Defined Table Types and employing Tabled-Valued Parameters. This makes it feasible to deliver a large amount of data with a single request rather than having to run the function numerous times (one for each data).
HostForLIFEASP.NET SQL Server 2022 Hosting
