This article demonstrates how we can easily rename various database objects like Tables, Columns, Constraints, Indexes, SP in SQL Server. You may have faced a scenario where sometimes we need to rename database objects to specify correct business significance and meaning to the system on production code. The database objects which were originally designed may not match the current business objects. To solve this problem, you may need to rename existing database objects like table name, column name, store procedure name, etc. The best and easiest way is to use SP_RENAME, a build-in stored procedure to rename these objects.
This approach is recommended because we can run pre-deployment scripts in the environment before deploying these changes.
SP_RENAME takes below arguments.
| Parameter |
Description |
| @objname |
Object Name. When renaming a column you need to specify table name.column name optionally you can also prefix schema name |
| @newname |
New name for the specified object |
| @objtype |
Type of the object. You can rename below objects using sp_rename:
COLUMN
DATABASE
INDEX
OBJECT
STATISTICS
USERDATATYPE
Default value for this parameter is TABLE |
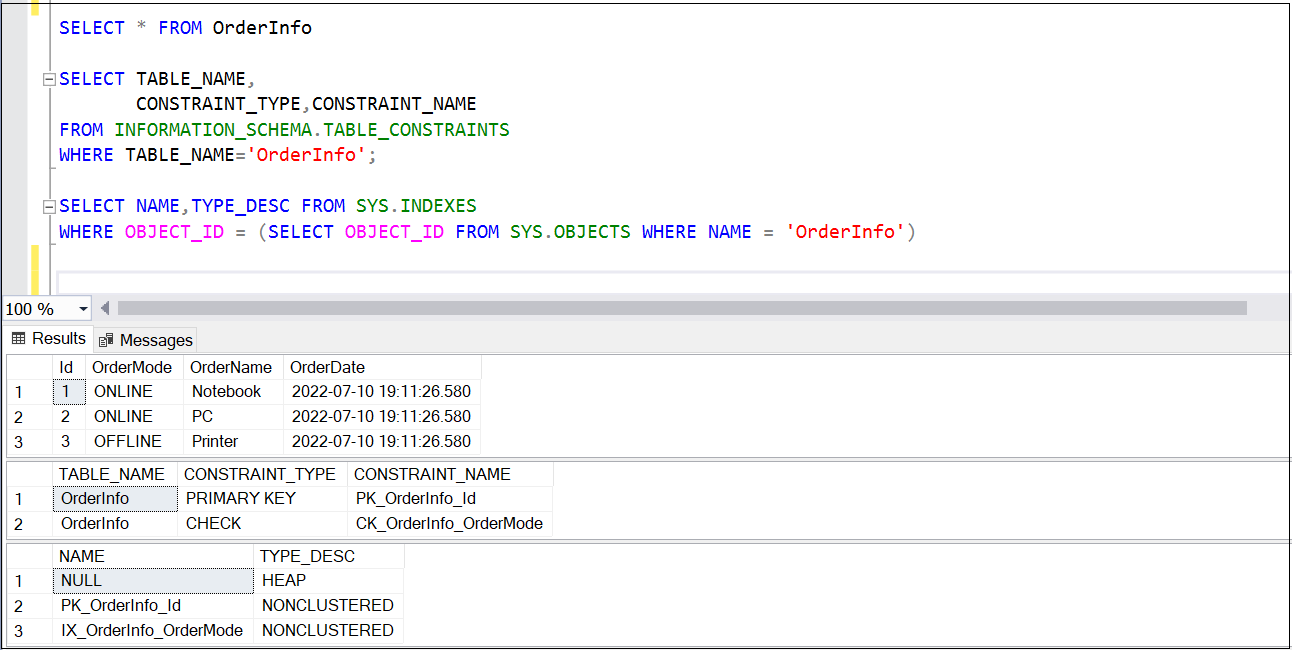
To demonstrates this, I am creating a table with Primary key, check constraint, non-clustered index and putting some data into this table. We will compare before and after snapshots.
CREATE TABLE OrderInfo
(
Id INT IDENTITY(1, 1) NOT NULL,
OrderMode VARCHAR(20) CONSTRAINT [CK_OrderInfo_OrderMode] CHECK (OrderMode IN ('ONLINE','OFFLINE')) NOT NULL,
OrderName VARCHAR(100) NOT NULL,
OrderDate DATETIME CONSTRAINT [DF_OrderInfo_OrderDate] DEFAULT (GETDATE()) NOT NULL,
CONSTRAINT PK_OrderInfo_Id PRIMARY KEY NONCLUSTERED (Id ASC)
)
CREATE NONCLUSTERED INDEX IX_OrderInfo_OrderMode ON dbo.OrderInfo (OrderMode)
INSERT INTO OrderInfo
VALUES
( 'ONLINE', 'Notebook', GETDATE()),
( 'ONLINE', 'PC', GETDATE()),
( 'OFFLINE', 'Printer', GETDATE())
GO
Before snapshot of table, constraints, and index.
Rename a Table
--Rename table OrderInfo to OrderSummary
EXEC SP_RENAME 'dbo.OrderInfo', 'OrderSummary'
Rename a Column
--Rename column Id to OrderSummaryId
IF EXISTS(SELECT 1 FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME= 'OrderSummary' AND COLUMN_NAME='Id')
BEGIN
EXEC SP_RENAME 'dbo.OrderSummary.Id', 'OrderSummaryId'
END
Rename an Index
--REANME INDEX
IF EXISTS (SELECT 1 FROM sys.indexes WHERE name='IX_OrderInfo_OrderMode' AND OBJECT_ID = OBJECT_ID('dbo.OrderSummary'))
BEGIN
EXEC SP_RENAME 'dbo.OrderSummary.IX_OrderInfo_OrderMode','IX_OrderSummary_OrderMode','INDEX';
END
Rename a Primary Key Constraint
--REANME PRIMARY KEY CONSTRAINT
IF EXISTS(SELECT 1 FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS WHERE CONSTRAINT_NAME ='PK_OrderInfo_Id')
BEGIN
EXEC SP_RENAME 'dbo.PK_OrderInfo_Id','PK_OrderSummary_OrderSummaryId','OBJECT';
END
Rename a Check Constraint
--REANME CHECK CONSTRAINT
IF EXISTS(SELECT 1 FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS WHERE CONSTRAINT_NAME ='CK_OrderInfo_OrderMode')
BEGIN
EXEC SP_RENAME 'dbo.CK_OrderInfo_OrderMode','CK_OrderSummary_OrderMode','OBJECT';
END
Rename a Stored Procedure
--RENAME SP
EXEC SP_RENAME 'dbo.spGetOrderInfoByOrderMode' , 'spGetOrderSummaryByOrderMode';
Let’s verify the changes have been made by issuing a SELECT against the table using new table name.
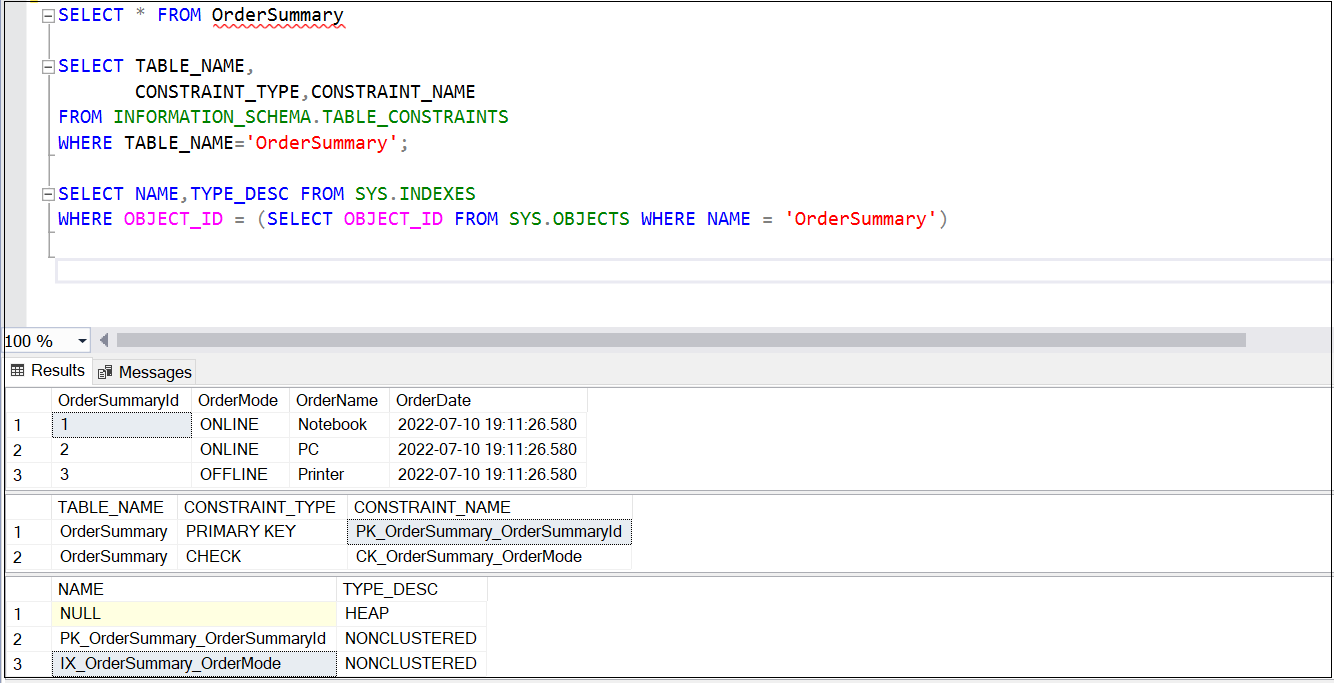
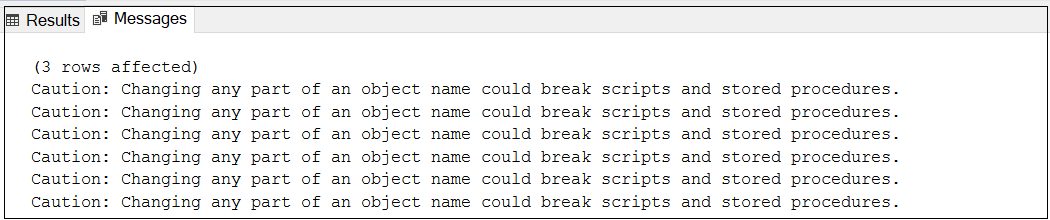
One thing to keep in mind is that when we rename these objects, we need to make changes in dependencies of these objects. For example – if you are renaming a table and that table is being used in multiple SPs then we also to modify those SPs as well. But that is a manual activity to find and fix. This warning represents the same thing.
Hope you find this information useful. Happy Learning!