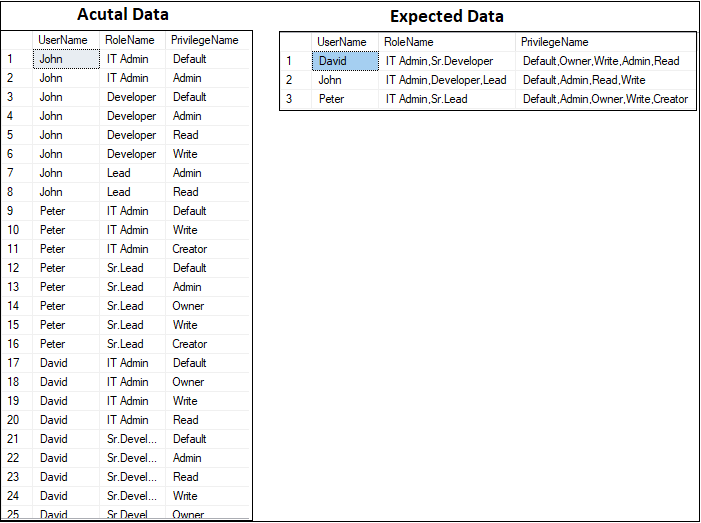
Our user belongs to several roles, each of which has a number of privileges associated with it. The responsibilities and privileges that are linked to each user are what users want to see. In order to prevent redundant roles and privileges, the final product should have distinct roles and privileges. Basically, we have to remove duplicates from the string separated by commas.
Let's look at the data—both real and predicted.
Solution
One of two methods can be used to solve this problem in SQL Server utilizing the STRING_AGG() function.
Method 1
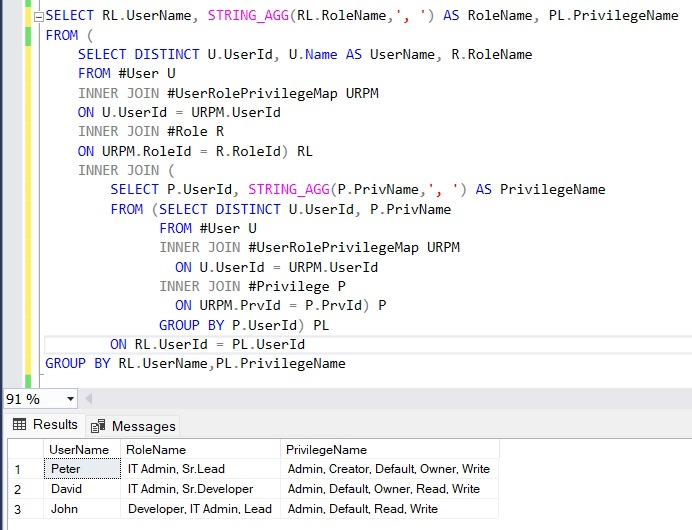
We may efficiently eliminate any duplicates by utilizing STRING_AGG() inside a subquery.
SELECT RL.UserName, STRING_AGG(RL.RoleName,', ') AS RoleName, PL.PrivilegeName
FROM (
SELECT DISTINCT U.UserId, U.Name AS UserName, R.RoleName
FROM #User U
INNER JOIN #UserRolePrivilegeMap URPM
ON U.UserId = URPM.UserId
INNER JOIN #Role R
ON URPM.RoleId = R.RoleId) RL
INNER JOIN (
SELECT P.UserId, STRING_AGG(P.PrivName,', ') AS PrivilegeName
FROM (SELECT DISTINCT U.UserId, P.PrivName
FROM #User U
INNER JOIN #UserRolePrivilegeMap URPM
ON U.UserId = URPM.UserId
INNER JOIN #Privilege P
ON URPM.PrvId = P.PrvId) P
GROUP BY P.UserId) PL
ON RL.UserId = PL.UserId
GROUP BY RL.UserName,PL.PrivilegeName
Expected Result
Method 2
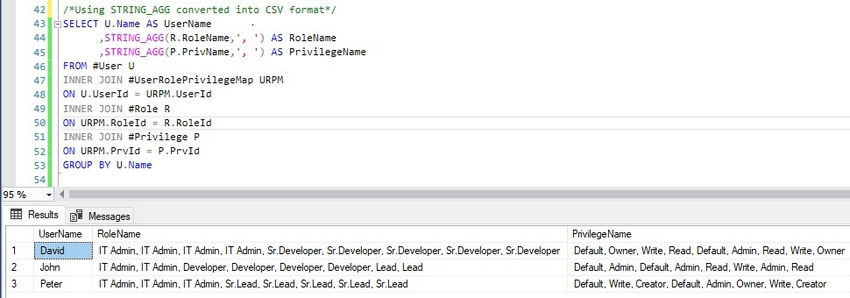
Rows can be converted to Comma-Separated Values (CSV) by utilizing the grouped concatenation method with STRING_AGG(). Then, we can use the XQuery function distinct-values() to retrieve unique values from the XML instance after converting the CSV file to XML.
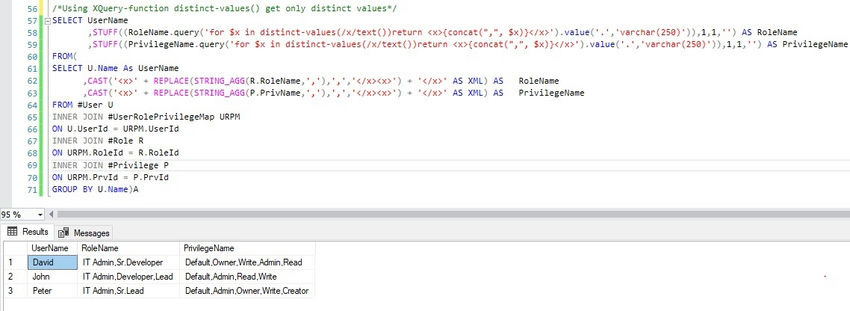
/*Using XQuery-function distinct-values() get only distinct values*/
SELECT UserName
,STUFF((RoleName.query('for $x in distinct-values(/x/text())return <x>{concat(",", $x)}</x>').value('.','varchar(250)')),1,1,'') AS RoleName
,STUFF((PrivilegeName.query('for $x in distinct-values(/x/text())return <x>{concat(",", $x)}</x>').value('.','varchar(250)')),1,1,'') AS PrivilegeName
FROM(
SELECT U.Name As UserName
,CAST('<x>' + REPLACE(STRING_AGG(R.RoleName,','),',','</x><x>') + '</x>' AS XML) AS RoleName
,CAST('<x>' + REPLACE(STRING_AGG(P.PrivName,','),',','</x><x>') + '</x>' AS XML) AS PrivilegeName
FROM #User U
INNER JOIN #UserRolePrivilegeMap URPM
ON U.UserId = URPM.UserId
INNER JOIN #Role R
ON URPM.RoleId = R.RoleId
INNER JOIN #Privilege P
ON URPM.PrvId = P.PrvId
GROUP BY U.Name)A
Step 1: Transform the real data into the CSV format indicated below by using the STRING_AGG() function.
Step 2. Next, convert the CSV into XML format.
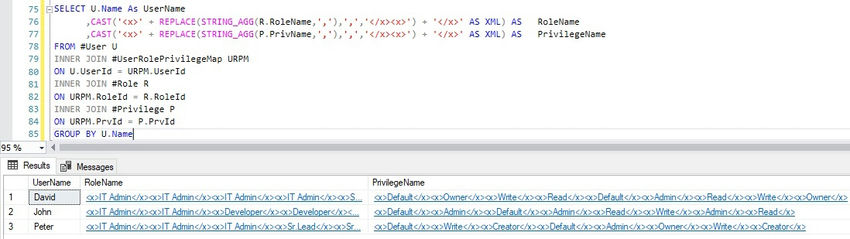
Step 3. Now, utilize the XQuery function distinct-values() to extract unique values from the XML instance.
Tables and Insert Scripts
/*Create USER Table and Insert Data*/
DROP TABLE IF EXISTS #User
CREATE TABLE #User (UserId INT, Name VARCHAR(50))
INSERT INTO #User (UserId, Name)
VALUES (1, 'John'),
(2, 'Peter'),
(3, 'David')
/*Create ROLE Table and Insert Data*/
DROP TABLE IF EXISTS #Role
CREATE TABLE #Role (RoleId INT, RoleName VARCHAR(50))
INSERT INTO #Role (RoleId, RoleName)
VALUES (1, 'IT Admin'), (2, 'Developer'), (3, 'Sr.Developer'), (4, 'Lead'), (5, 'Sr.Lead')
/*Create PRIVILEGE Table and Insert Data*/
DROP TABLE IF EXISTS #Privilege
CREATE TABLE #Privilege (PrvId INT, PrivName VARCHAR(50))
INSERT INTO #Privilege (PrvId, PrivName)
VALUES (1, 'Default'), (2, 'Admin'), (3, 'Creator'), (4, 'Read'), (5, 'Write'), (6, 'Owner')
/*Create USERROLEPRIVILEGEMAP Table and Insert Data*/
DROP TABLE IF EXISTS #UserRolePrivilegeMap
CREATE TABLE #UserRolePrivilegeMap(UserId INT, RoleId INT, PrvId INT)
INSERT INTO #UserRolePrivilegeMap (UserId, RoleId, PrvId)
VALUES (1,1,1), (1,1,2), (1,2,1), (1,2,2), (1,2,4), (1,2,5), (1,4,2),
(1,4,4), (2,1,1), (2,1,5), (2,1,3), (2,5,1), (2,5,2), (2,5,6),
(2,5,5), (2,5,3), (3,1,1), (3,1,6), (3,1,5), (3,1,4), (3,3,1),
(3,3,2), (3,3,4), (3,3,5), (3,3,6)
/*Join all tables and get the actual data*/
SELECT U.Name AS UserName
,R.RoleName
,P.PrivName AS PrivilegeName
FROM #User U
INNER JOIN #UserRolePrivilegeMap URPM
ON U.UserId = URPM.UserId
INNER JOIN #Role R
ON URPM.RoleId = R.RoleId
INNER JOIN #Privilege P
ON URPM.PrvId = P.PrvId
Conclusion
Efficiently convert row data into comma-separated values using SQL Server's string aggregate function, ensuring duplicates are removed for streamlined data representation and integrity.
HostForLIFEASP.NET SQL Server 2022 Hosting
