
March 1, 2021 06:14 by
 Peter
PeterWe use merge statement when we have to merge data from the source table to the target table. Based on the condition specified it will Insert, Update and Delete rows in the targeted table all within the same statement. Merge statement is very useful when we have large data tables to load, especially when specific actions to be taken when rows are matching and when they are not matching.
The statement has many practical uses in both online transaction processing (OLTP) scenarios and in data warehousing ones. As an example of an OLTP use case, suppose that you have a table that isn’t updated directly by your application and instead, you get a delta of changes periodically from an external system. You first load the delta of changes into a staging table and then use the staging table as the source for the merge operation into the target.
The below diagram shows the source table and target table with corresponding actions: Insert, Delete and Update
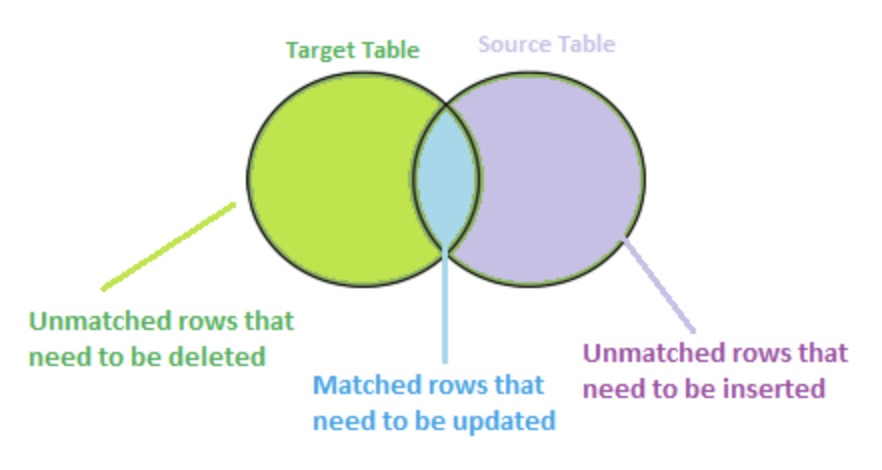
It shows three use cases,
When the source table has some rows matching that do not exist in the target table, then we have to insert these rows to the target table.
When the target table has some rows that do not exist in the source table, then we have to delete these rows from the target table.
When the source table has some keys matching keys with the target table, then we need to update the rows in a targeted table with the values coming from the source table.
Below is the basic structure of the Merge statement,
MERGE INTO <target_table> AS TGT USING <source_table> AS SRC
ON <merge_condition>
WHEN MATCHED
THEN update_statement -- When we have a key matching row
WHEN NOT MATCHED
THEN insert_statement -- when row exists in the source table and doesn't exist in the target table
WHEN NOT MATCHED BY SOURCE
THEN DELETE; -- Row doesn't exist in the source table
Consider the below example,
It is very easy to understand the merging concept here. We have two tables, the source table and a target table. The Source table has a new price for fruits [ex: Orange rate changed from 15.00 to 25.00] and also new fruits arrived at the store. When we merge we are deleting a few rows which do not exist in the source table.
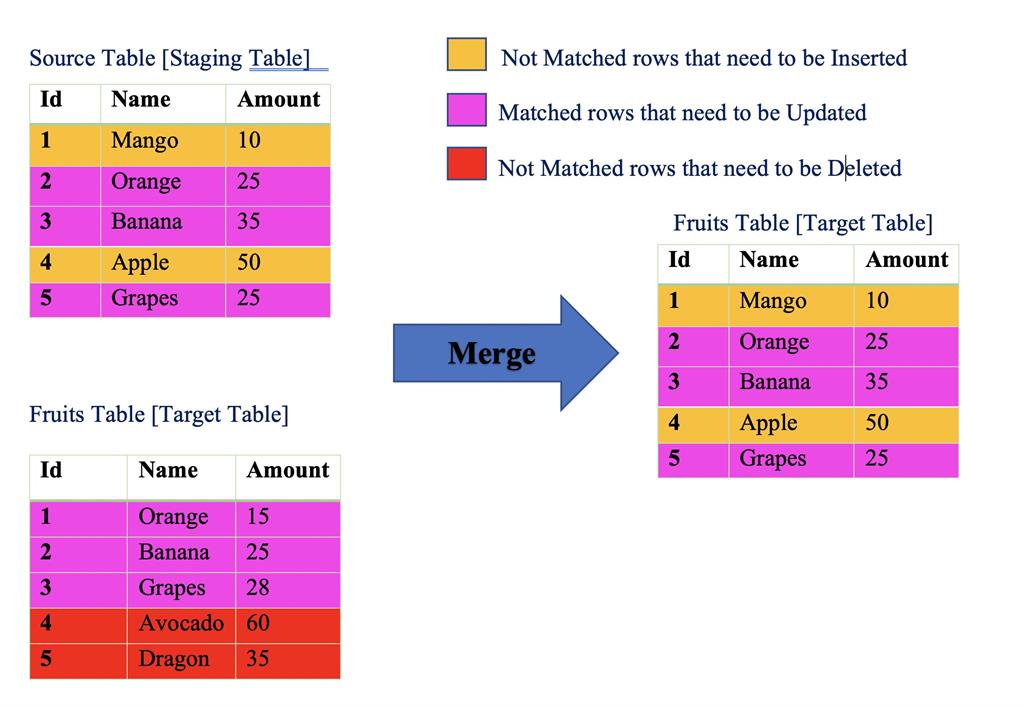
Merge Statement In SQL
Code to merge tables.
MERGE INTO Fruits WITH(SERIALIZABLE) f
USING source s
ON (s.id = f.id)
WHEN MATCHED
THEN UPDATE SET
f.name= s.name,
f.amount = s.amount
WHEN NOT MATCHED BY TARGET
THEN INSERT (id, name, amount) VALUES (s.id, s.name, s.amount)
WHEN NOT MATCHED BY SOURCE
THEN DELETE;
SELECT @@ROWCOUNT;
GO
Important Merge Conflict
Suppose that a certain key K doesn’t yet exist in the target table. Two processes, P1 and P2, run a MERGE statement such as the previous one at the same time with the same source key K. It is normally possible for the MERGE statement issued by P1 to insert a new row with the key K between the points in time when the MERGE statement issued by P2 checks whether the target already has that key and inserts rows. In such a case, the MERGE statement issued by P2 fails due to a primary key violation. To prevent such a failure, use the hint SERIALIZABLE or HOLDLOCK (both have equivalent meanings) against the target as shown in the previous statement. This hint means that the statement uses a serializable isolation level to serialize access to the data, meaning that once you get access to the data, it’s as if you’re the only one interacting with it.
In this article, we learned how a Merge statement improves performance by reading and processing data in a single query. There is no need to write three different statements. This will avoid multiple I/O operations from the disk for each of three statements individually because now data is read only once from the source table.
HostForLIFEASP.NET SQL Server 2019 Hosting
