In some cases, using the CASE statement can lead to numerous conditions. You may agree or not; these multiple conditions will look extensive and lengthy in some situations. Moreover, it can be challenging to maintain because of its complexity.
That's why in this post, we'll explore CHOOSE function. It helps developers have a better alternative to the CASE statement when simplifying lengthy conditions.
What's CHOOSE Function in SQL Server?
Introduced in SQL Server 2012
A function returns a specific value from a list based on its number index.
It looks like an array, but the index starts from 1.
Syntax
CHOOSE (INDEX, VALUE1, VALUE2, VALUE3, VALUE4...)
Index
This is the element's position we seek in the output. Remember that CHOOSE doesn't use a zero-based index strategy (meaning the first item starts with 1). If in case the index is not an integer, SQL converts it to an integer otherwise returns NULL.
Values
It is a comma-separated list of any data type. Returns an item based on the index specified in the first(index) parameter.
Examples
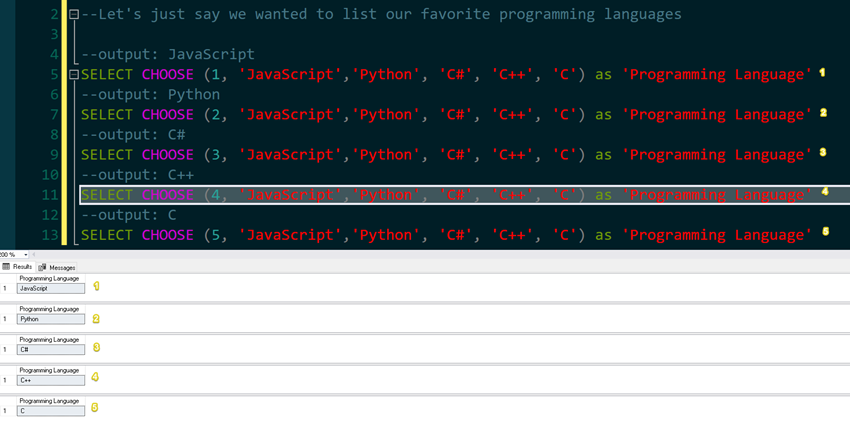
1. Item index starts at 1
--Let's just say we wanted to list our favorite programming languages
--output: JavaScript
SELECT CHOOSE (1, 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
--output: Python
SELECT CHOOSE (2, 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
--output: C#
SELECT CHOOSE (3, 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
--output: C++
SELECT CHOOSE (4, 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
--output: C
SELECT CHOOSE (5, 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
Output
2. When CHOOSE Function Returns NULL
--output: NULL
SELECT CHOOSE (0, 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
--output: NULL
SELECT CHOOSE (6, 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
Output
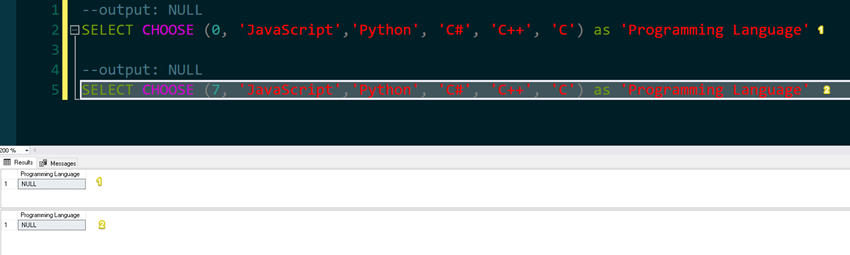
If we have passed the index outside the value list range, you'll be getting NULL as the return value.
3. Using Float or Decimal as Index Values
--output: NULL
SELECT CHOOSE (0.10, 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
--output: JavaScript
SELECT CHOOSE (1.10, 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
--output: Python
SELECT CHOOSE (2.23, 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
--output: C#
SELECT CHOOSE (3.9923423, 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
--output: C++
SELECT CHOOSE (4.7412122, 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
--output: C
SELECT CHOOSE (5, 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
--output: NULL
SELECT CHOOSE (6.636, 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
Output
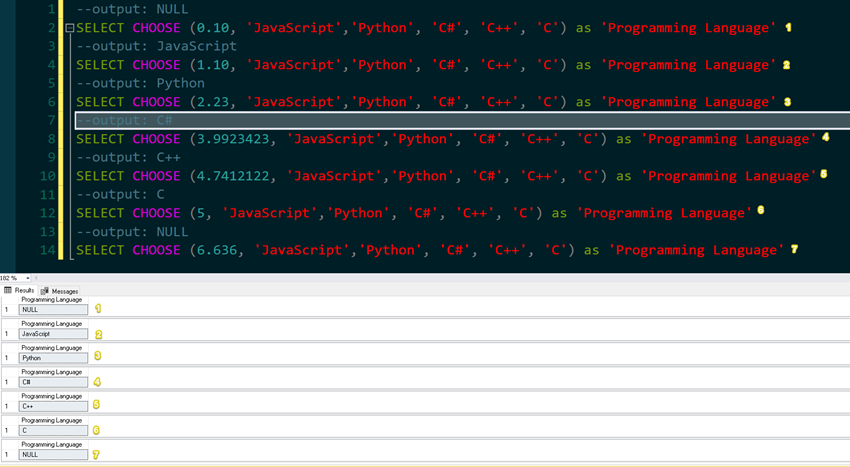
In our example above, we have seen that once we have passed a float or decimal data type, the value is implicitly converted into an integer as long as it's not int. We'll have the same output as from the first two examples.
4. Using String as Index-values
In this section, you'll see that we can still pass a string that has an integer value.
Let's see an example below.
--Let's just say we wanted to list our favorite programming languages
-- This time around, we'll use string but with a correct integer index
--output: JavaScript
SELECT CHOOSE ('1', 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
--output: Python
SELECT CHOOSE ('2', 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
--output: C#
SELECT CHOOSE ('3', 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
--output: C++
SELECT CHOOSE ('4', 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
--output: C
SELECT CHOOSE ('5', 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
Output
However, if we pass a non-integer value like an alphanumeric value or decimal value, it will throw an exception.
Let's see an example below.
--output: exception
SELECT CHOOSE ('One', 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
--output: exception
SELECT CHOOSE ('1.15', 'JavaScript','Python', 'C#', 'C++', 'C') as 'Programming Language'
5. Using CHOOSE in a SELECT Statements
This time, we'll be using the AdventureWorks database and trying to see the employees' birth months. By the way, we'll be using two tables [HumanResources].[Employee] and [Person].[Person] for us to get the names of the employees and show the birth months.
Let's see the example below.
SELECT
FORMATMESSAGE('%s, %s %s',
P.[LastName],
P.[FirstName],
ISNULL(P.[MiddleName], '')) AS [FullName],
E.[BirthDate],
CHOOSE(MONTH(E.[BirthDate]), 'Jan.',
'Feb.',
'Mar.',
'Apr.',
'May.',
'Jun.',
'Jul.',
'Aug.',
'Sep',
'Oct.',
'Nov.',
'Dec.') as [Birth Month]
FROM
[AdventureWorks2019].[HumanResources].[Employee] E
INNER JOIN [Person].[Person] P ON
E.[BusinessEntityID] = P.[BusinessEntityID]
HostForLIFEASP.NET SQL Server 2021 Hosting
