Sounds impossible, right? The saying goes that you can never be too rich or too thin or have too much memory.
However, there is one good indication that your SQL Server is probably overprovisioned, and to explain it, I need to cover 3 metrics.
1. Max Server Memory is set at the instance level: right-click on your SQL Server name in SSMS, click Properties, Memory, and it’s “Maximum server memory.” This is how much memory you’re willing to let the engine use. (The rocket surgeons in the audience are desperate for the chance to raise their hands to point out different things that are or aren’t included in max memory – hold that thought. That’s a different blog post.)
2. Target Server Memory is how much memory the engine is willing to use. You can track this with the Perfmon counter SQLServer:Memory Manager – Target Server Memory (KB):
SELECT *
FROM sys.dm_os_performance_counters
WHERE counter_name LIKE '%Target Server%';
Generally, when you start up SQL Server, the target is set at your max. However, SQL Server doesn’t allocate all of that memory by default. (Again, the experts wanna raise hands and prove how much they know – zip it.)
3. Total Server Memory is roughly how much the engine is actually using. (Neckbeards – seriously – zip it until the end of the post. I’m not playing.) After startup, SQL Server will gradually use more and more memory as your queries require it. Scan a big index? SQL Server will start caching as much of that index as it can in memory. You’ll see this number increase over time until – generally speaking – it matches target server memory.
SELECT *
FROM sys.dm_os_performance_counters
WHERE counter_name LIKE '%Total Server%';
What if Total Server Memory doesn’t go up?
Say you have a SQL Server with:
Infrequent query workloads (we don’t have hundreds of users trying to sort the database’s biggest table simultaneously, or do cartesian joins)
SQL Server might just not ever need the memory.
And in a situation like this, after a restart, you’ll see Total Server Memory go up to 2-3GB and call it a day. It never rises up to 10GB, let alone 60GB. That means this SQL Server just has more memory than it needs.
Here’s an example of a server that was restarted several days ago, and still hasn’t used 4GB of its 85GB max memory setting. Here, I’m not showing max memory – just the OS in the VM, and target and total:
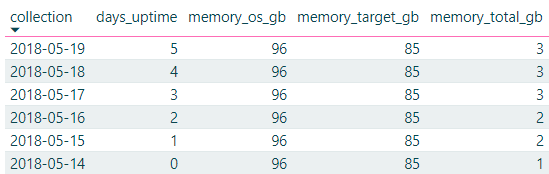
In most cases, it’s not quite that black-and-white, but you can still use the speed at which Total Server Memory rises after a reboot to get a rough indication of how badly (and quickly) SQL Server needs that memory. If it goes up to Target Server Memory within a couple of hours, yep, you want that memory bad. But if it takes days? Maybe memory isn’t this server’s biggest challenge.
Exceptions obviously apply – for example, you might have an accounting server that only sees its busiest activity during close of business periods. Its memory needs might be very strong then, but not such a big deal the rest of the month.