In this article, we will learn how to create a database backup scheduler in the SQL Express version as it has no built-in auto backup tool like SQL Server. With the help of Task Scheduler (Windows OS) and batch file, we will create a schedular to take the database backup from the SQL Express version in the specified folder.
Requirement
Batch File
Stored Procedure (Database Backup) which is not available in SQL Express version
Configuration on Windows Task Scheduler
Let's get started,
Batch File
Create a batch file as below,
Open notepad and paste the below code and change the parameters as per your configuration and save this file as a .bat extension.
sqlcmd -S .\SQLEXPRESS_Instance_Name -E -Q "EXEC sp_BackupDatabases @backupLocation='D:\Backup\', @databaseName='DatabaseName', @backupType='F'"
ActionScript
In the above statement, sp_BackupDatabases is a stored procedure name that we will create in the next step.
Stored Procedure (Database Backup)
In SQL Express we have to add the below-stored procedure in the default Master database as SQL Express does not provide built-in auto back feature.
We will create the below-stored procedure in the Master database which is a default database provided by SQL Express.
Note
The below-stored procedure is written by Microsoft.
Copied from https://raw.githubusercontent.com/microsoft/mssql-support/master/sample-scripts/backup_restore/SQL_Express_Backups.sql
USE [master]
GO
/****** Object: StoredProcedure [dbo].[sp_BackupDatabases] Script Date: 17/07/2021 11:35:01 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
-- =============================================
-- Author: Microsoft
-- Create date: 2010-02-06
-- Description: Backup Databases for SQLExpress
-- Parameter1: databaseName
-- Parameter2: backupType F=full, D=differential, L=log
-- Parameter3: backup file location
-- =============================================
ALTER PROCEDURE [dbo].[sp_BackupDatabases]
@databaseName sysname = null,
@backupType CHAR(1),
@backupLocation nvarchar(200)
AS
SET NOCOUNT ON;
DECLARE @DBs TABLE
(
ID int IDENTITY PRIMARY KEY,
DBNAME nvarchar(500)
)
-- Pick out only databases which are online in case ALL databases are chosen to be backed up
-- If specific database is chosen to be backed up only pick that out from @DBs
INSERT INTO @DBs (DBNAME)
SELECT Name FROM master.sys.databases
where state=0
AND name= ISNULL(@DatabaseName ,name)
ORDER BY Name
-- Filter out databases which do not need to backed up
IF @backupType='F'
BEGIN
DELETE @DBs where DBNAME IN ('tempdb','Northwind','pubs','AdventureWorks')
END
ELSE IF @backupType='D'
BEGIN
DELETE @DBs where DBNAME IN ('tempdb','Northwind','pubs','master','AdventureWorks')
END
ELSE IF @backupType='L'
BEGIN
DELETE @DBs where DBNAME IN ('tempdb','Northwind','pubs','master','AdventureWorks')
END
ELSE
BEGIN
RETURN
END
-- Declare variables
DECLARE @BackupName varchar(100)
DECLARE @BackupFile varchar(100)
DECLARE @DBNAME varchar(300)
DECLARE @sqlCommand NVARCHAR(1000)
DECLARE @dateTime NVARCHAR(20)
DECLARE @Loop int
-- Loop through the databases one by one
SELECT @Loop = min(ID) FROM @DBs
WHILE @Loop IS NOT NULL
BEGIN
-- Database Names have to be in [dbname] format since some have - or _ in their name
SET @DBNAME = '['+(SELECT DBNAME FROM @DBs WHERE ID = @Loop)+']'
-- Set the current date and time n yyyyhhmmss format
SET @dateTime = REPLACE(CONVERT(VARCHAR, GETDATE(),101),'/','') + '_' + REPLACE(CONVERT(VARCHAR, GETDATE(),108),':','')
-- Create backup filename in path\filename.extension format for full,diff and log backups
IF @backupType = 'F'
SET @BackupFile = @backupLocation+REPLACE(REPLACE(@DBNAME, '[',''),']','')+ '_FULL_'+ @dateTime+ '.BAK'
ELSE IF @backupType = 'D'
SET @BackupFile = @backupLocation+REPLACE(REPLACE(@DBNAME, '[',''),']','')+ '_DIFF_'+ @dateTime+ '.BAK'
ELSE IF @backupType = 'L'
SET @BackupFile = @backupLocation+REPLACE(REPLACE(@DBNAME, '[',''),']','')+ '_LOG_'+ @dateTime+ '.TRN'
-- Provide the backup a name for storing in the media
IF @backupType = 'F'
SET @BackupName = REPLACE(REPLACE(@DBNAME,'[',''),']','') +' full backup for '+ @dateTime
IF @backupType = 'D'
SET @BackupName = REPLACE(REPLACE(@DBNAME,'[',''),']','') +' differential backup for '+ @dateTime
IF @backupType = 'L'
SET @BackupName = REPLACE(REPLACE(@DBNAME,'[',''),']','') +' log backup for '+ @dateTime
-- Generate the dynamic SQL command to be executed
IF @backupType = 'F'
BEGIN
SET @sqlCommand = 'BACKUP DATABASE ' +@DBNAME+ ' TO DISK = '''+@BackupFile+ ''' WITH INIT, NAME= ''' +@BackupName+''', NOSKIP, NOFORMAT'
END
IF @backupType = 'D'
BEGIN
SET @sqlCommand = 'BACKUP DATABASE ' +@DBNAME+ ' TO DISK = '''+@BackupFile+ ''' WITH DIFFERENTIAL, INIT, NAME= ''' +@BackupName+''', NOSKIP, NOFORMAT'
END
IF @backupType = 'L'
BEGIN
SET @sqlCommand = 'BACKUP LOG ' +@DBNAME+ ' TO DISK = '''+@BackupFile+ ''' WITH INIT, NAME= ''' +@BackupName+''', NOSKIP, NOFORMAT'
END
-- Execute the generated SQL command
EXEC(@sqlCommand)
-- Goto the next database
SELECT @Loop = min(ID) FROM @DBs where ID>@Loop
END
Windows Task Scheduler Configuration
Now we will create a windows scheduler to run the batch file to run the above-stored procedure to create an automated backup which is a final step.
Open Task Scheduler as below (type task scheduler from the search bar of windows 10 and press enter).
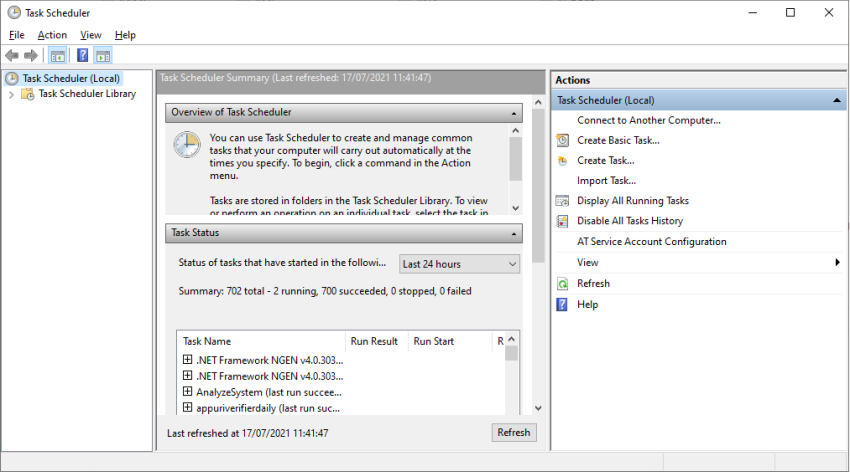
Create a new task as below,
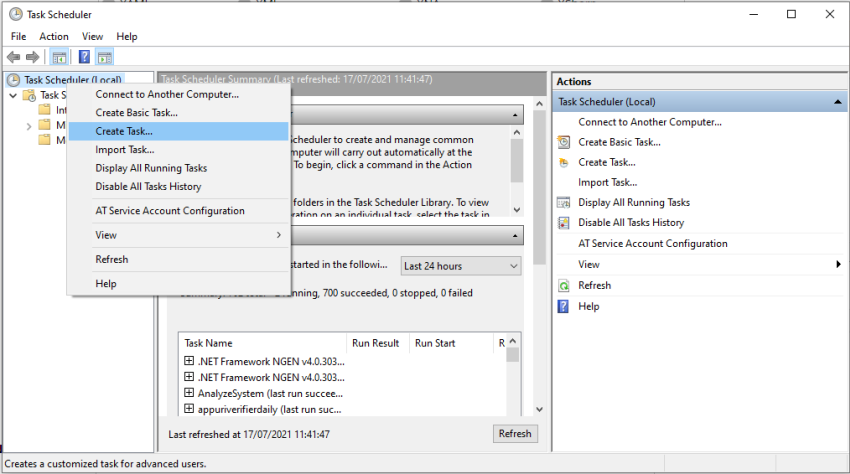
We will give the name to our scheduler task and select the appropriate option as below. We need to run this scheduler all time so we select this selected option shown below screen.
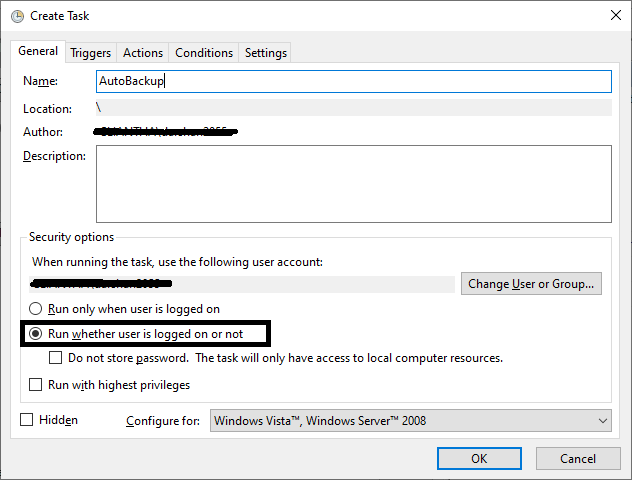
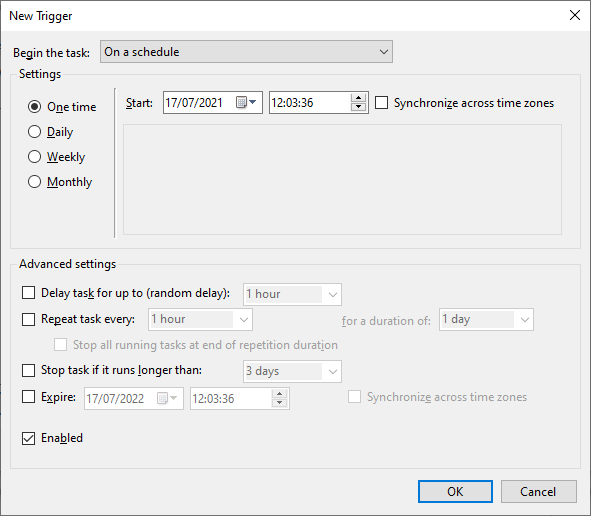
Now we will set our scheduler - when to run this task using the Trigger tab as below screen and then click on the new button.
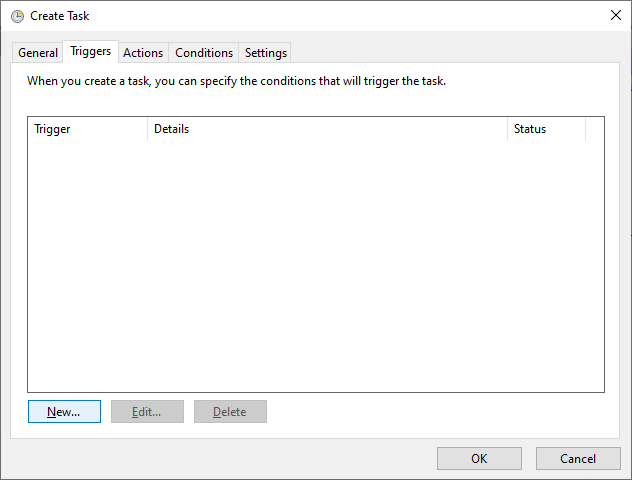
Now will create a new trigger to tell the system when to run this task as below. Please configure it as per your requirement.
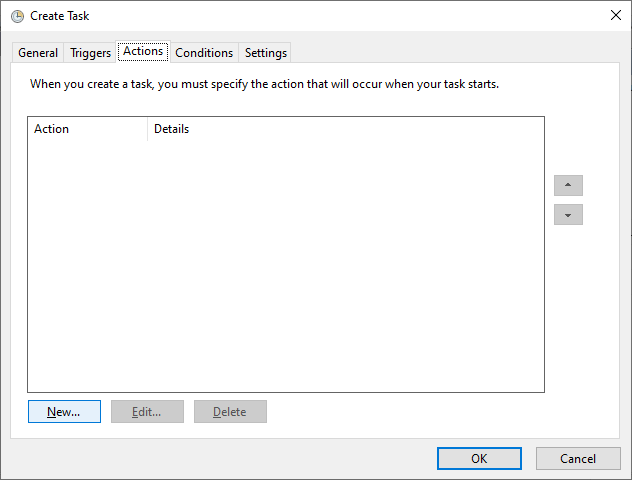
Once the trigger is set we will now configure the action tab and then click the new button to setup our above-created batch file. We will call our batch file with the help of the action tab as below,
Click on the new button to set the path of our batch file as below,
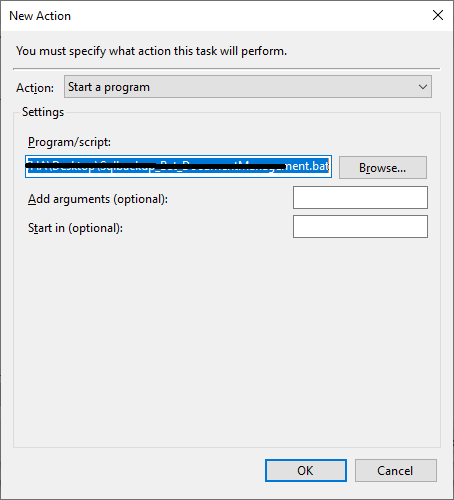
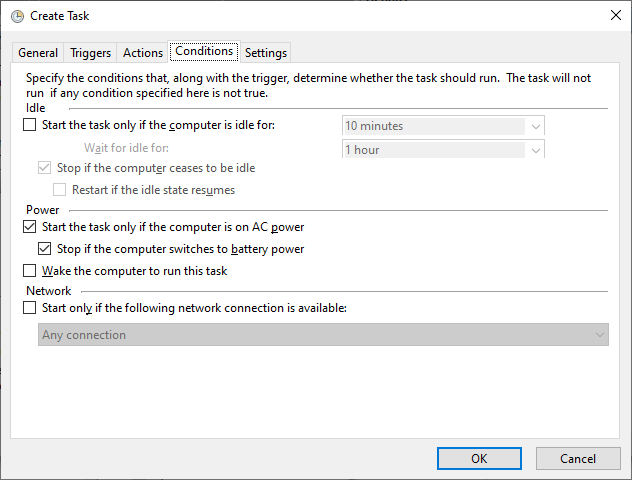
Once we browse and select the created batch file then click the ok button. And then click on the condition tab to configure it. We will keep default settings as below,
And now final configuration, click on the settings tab as below. Again we will keep default settings as below,
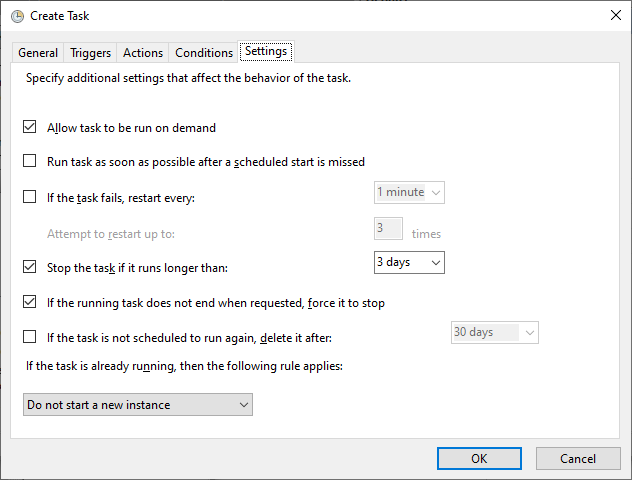
Click the ok button will create your task and will run this task as per your configuration. Note: It will ask to enter windows credentials which have admin rights if you do not have enough rights to create such a task.
Once all set, the scheduler will run the task to call the batch file and that batch file will call the stored procedure to get the backup of mentioned database in the batch file.
Note
Please make sure that the information you mention in the batch is correct.
Happy Coding!!
HostForLIFEASP.NET SQL Server 2019 Hosting
