We will learn what CTE is, how to construct it in SQL Server, and its applications in this article.
CTE: What is it?
"Common Table Expressions" is what CTE stands for. SQL servers utilize it to specify a temporary name result. The common table expression (CTE) is a temporary named result set that can be referenced within a Select, Insert, Update, or Delete operation. It was first introduced in SQL Server 2005. Another crucial point is that, like any other table, CTE results can always be accessed within the query even when they are not saved anywhere.
Why do we need CTE on the SQL server?
CTE is a powerful SQL feature that helps simplify queries. CTEs act as virtual tables (with records and columns) that are created during query execution, used by the query, and deleted after the query executes.
Syntax
[ WITH <common_table_expression> [ ,...n ] ]
<common_table_expression>::=
expression_name [ ( column_name [ ,...n ] ) ]
AS
( CTE_query_definition )
Let’s try to understand CTE Syntax.
Arguments
There are three arguments in the above syntax.
- expression_name.
- column_name.
- query_derfination.
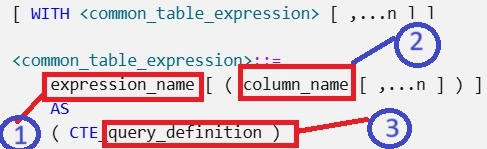
Let’s understand one by one.
- expression_name: It should be a valid identifier for a common table expression. The expression_name must be different from the names of other common table expressions defined in the same WITH clause.
- column_name: Specifies a column name in the common table expression. Duplicate names are not allowed within a single CTE definition. There are two rules for column names. The first is the number of column names specified, which must match the number of columns in the result set of the query_definition, and the second one is The list of column names is optional only if distinct names for all resulting columns are supplied in the query definition.
- query_defination: Specifies a SELECT statement whose result set satisfies a common table expression.
Some Examples
Before starting to explain some CTE examples, we need to create a database and some tables under the database, so run the following script in your SQL server.
USE [master]
GO
/****** Object: Database [db_MyPractice] Script Date: 06-10-2024 01:18:01 ******/
CREATE DATABASE [db_MyPractice]
CONTAINMENT = NONE
ON PRIMARY
(
NAME = N'db_MyPractice',
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL15.SQLEXPRESS\MSSQL\DATA\db_MyPractice.mdf',
SIZE = 8192KB,
MAXSIZE = UNLIMITED,
FILEGROWTH = 65536KB
)
LOG ON
(
NAME = N'db_MyPractice_log',
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL15.SQLEXPRESS\MSSQL\DATA\db_MyPractice_log.ldf',
SIZE = 8192KB,
MAXSIZE = 2048GB,
FILEGROWTH = 65536KB
)
WITH CATALOG_COLLATION = DATABASE_DEFAULT
GO
ALTER DATABASE [db_MyPractice] SET COMPATIBILITY_LEVEL = 150
GO
IF (1 = FULLTEXTSERVICEPROPERTY('IsFullTextInstalled'))
BEGIN
EXEC [db_MyPractice].[dbo].[sp_fulltext_database] @action = 'enable'
END
GO
ALTER DATABASE [db_MyPractice] SET ANSI_NULL_DEFAULT OFF
GO
ALTER DATABASE [db_MyPractice] SET ANSI_NULLS OFF
GO
ALTER DATABASE [db_MyPractice] SET ANSI_PADDING OFF
GO
ALTER DATABASE [db_MyPractice] SET ANSI_WARNINGS OFF
GO
ALTER DATABASE [db_MyPractice] SET ARITHABORT OFF
GO
ALTER DATABASE [db_MyPractice] SET AUTO_CLOSE OFF
GO
ALTER DATABASE [db_MyPractice] SET AUTO_SHRINK OFF
GO
ALTER DATABASE [db_MyPractice] SET AUTO_UPDATE_STATISTICS ON
GO
ALTER DATABASE [db_MyPractice] SET CURSOR_CLOSE_ON_COMMIT OFF
GO
ALTER DATABASE [db_MyPractice] SET CURSOR_DEFAULT GLOBAL
GO
ALTER DATABASE [db_MyPractice] SET CONCAT_NULL_YIELDS_NULL OFF
GO
ALTER DATABASE [db_MyPractice] SET NUMERIC_ROUNDABORT OFF
GO
ALTER DATABASE [db_MyPractice] SET QUOTED_IDENTIFIER OFF
GO
ALTER DATABASE [db_MyPractice] SET RECURSIVE_TRIGGERS OFF
GO
ALTER DATABASE [db_MyPractice] SET DISABLE_BROKER
GO
ALTER DATABASE [db_MyPractice] SET AUTO_UPDATE_STATISTICS_ASYNC OFF
GO
ALTER DATABASE [db_MyPractice] SET DATE_CORRELATION_OPTIMIZATION OFF
GO
ALTER DATABASE [db_MyPractice] SET TRUSTWORTHY OFF
GO
ALTER DATABASE [db_MyPractice] SET ALLOW_SNAPSHOT_ISOLATION OFF
GO
ALTER DATABASE [db_MyPractice] SET PARAMETERIZATION SIMPLE
GO
ALTER DATABASE [db_MyPractice] SET READ_COMMITTED_SNAPSHOT OFF
GO
ALTER DATABASE [db_MyPractice] SET HONOR_BROKER_PRIORITY OFF
GO
ALTER DATABASE [db_MyPractice] SET RECOVERY SIMPLE
GO
ALTER DATABASE [db_MyPractice] SET MULTI_USER
GO
ALTER DATABASE [db_MyPractice] SET PAGE_VERIFY CHECKSUM
GO
ALTER DATABASE [db_MyPractice] SET DB_CHAINING OFF
GO
ALTER DATABASE [db_MyPractice] SET FILESTREAM (NON_TRANSACTED_ACCESS = OFF)
GO
ALTER DATABASE [db_MyPractice] SET TARGET_RECOVERY_TIME = 60 SECONDS
GO
ALTER DATABASE [db_MyPractice] SET DELAYED_DURABILITY = DISABLED
GO
ALTER DATABASE [db_MyPractice] SET ACCELERATED_DATABASE_RECOVERY = OFF
GO
ALTER DATABASE [db_MyPractice] SET QUERY_STORE = OFF
GO
USE [db_MyPractice]
GO
/****** Object: Table [dbo].[Employees] Script Date: 06-10-2024 01:18:01 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[Employees] (
[EmployeeID] [smallint] NOT NULL,
NOT NULL,
NOT NULL,
NOT NULL,
[DeptID] [smallint] NOT NULL,
[ManagerID] [smallint] NULL,
CONSTRAINT [PK_EmployeeID] PRIMARY KEY CLUSTERED
(
[EmployeeID] ASC
) WITH (
PAD_INDEX = OFF,
STATISTICS_NORECOMPUTE = OFF,
IGNORE_DUP_KEY = OFF,
ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON,
OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF
) ON [PRIMARY]
) ON [PRIMARY]
GO
/****** Object: Table [dbo].[tbl_book] Script Date: 06-10-2024 01:18:01 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[tbl_book] (
[BookId] [bigint] IDENTITY(1,1) NOT NULL,
NOT NULL,
NOT NULL
) ON [PRIMARY]
GO
/****** Object: Table [dbo].[Tbl_Bookissued] Script Date: 06-10-2024 01:18:01 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[Tbl_Bookissued] (
[transaction_id] [bigint] IDENTITY(1,1) NOT NULL,
[StudentID] [bigint] NULL,
[TeacherID] [bigint] NULL,
[BookID] [bigint] NOT NULL,
[issueDate] [date] NOT NULL
) ON [PRIMARY]
GO
/****** Object: Table [dbo].[tbl_student] Script Date: 06-10-2024 01:18:01 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[tbl_student] (
[StudentID] [bigint] IDENTITY(1,1) NOT NULL,
NOT NULL
) ON [PRIMARY]
GO
/****** Object: Table [dbo].[tbl_teacher] Script Date: 06-10-2024 01:18:01 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[tbl_teacher] (
[TeacherID] [bigint] IDENTITY(1,1) NOT NULL,
NOT NULL
) ON [PRIMARY]
GO
-- Insert statements
INSERT [dbo].[Employees] ([EmployeeID], [FirstName], [LastName], [Title], [DeptID], [ManagerID]) VALUES
(1, N'Ken', N'Sánchez', N'Chief Executive Officer', 16, NULL),
(16, N'David', N'Bradley', N'Marketing Manager', 4, 273),
(23, N'Mary', N'Gibson', N'Marketing Specialist', 4, 16),
(273, N'Brian', N'Welcker', N'Vice President of Sales', 3, 1),
(274, N'Stephen', N'Jiang', N'North American Sales Manager', 3, 273),
(275, N'Michael', N'Blythe', N'Sales Representative', 3, 274),
(276, N'Linda', N'Mitchell', N'Sales Representative', 3, 274),
(285, N'Syed', N'Abbas', N'Pacific Sales Manager', 3, 273),
(286, N'Lynn', N'Tsoflias', N'Sales Representative', 3, 285)
GO
SET IDENTITY_INSERT [dbo].[tbl_book] ON
GO
INSERT [dbo].[tbl_book] ([BookId], [bookName], [className]) VALUES
(1, N'Maths', N'Class-1'),
(2, N'Maths', N'Class-2'),
(3, N'Maths', N'Class-3'),
(4, N'Maths', N'Class-4'),
(5, N'Maths', N'Class-5'),
(6, N'Maths', N'Class-6'),
(7, N'Hindi', N'Class-1'),
(8, N'Hindi', N'Class-2'),
(9, N'Hindi', N'Class-3'),
(10, N'Hindi', N'Class-4'),
(11, N'Hindi', N'Class-5'),
(12, N'Hindi', N'Class-6'),
(13, N'English', N'Class-1'),
(14, N'English', N'Class-2'),
(15, N'English', N'Class-3'),
(16, N'English', N'Class-4'),
(17, N'English', N'Class-5'),
(18, N'English', N'Class-6')
GO
SET IDENTITY_INSERT [dbo].[tbl_book] OFF
After running this script, you will have the following table. Following tables with data.
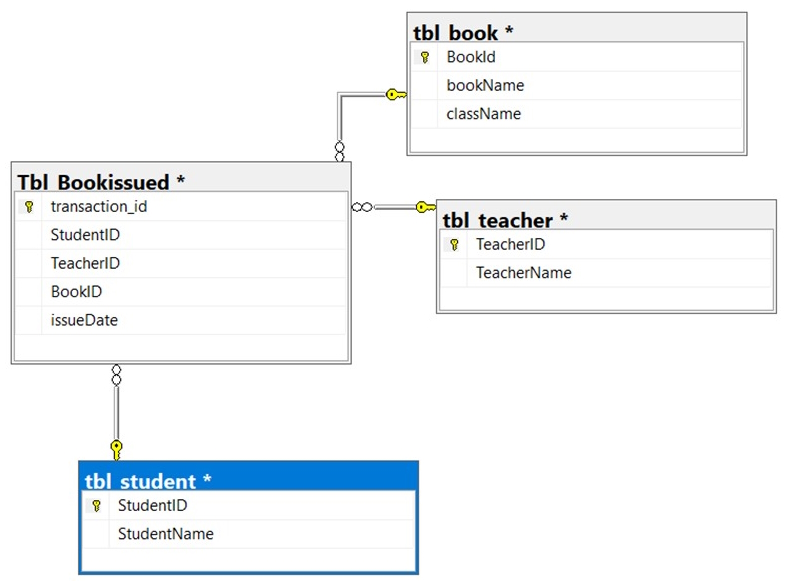
A. Create a common table expression: The following example shows the total number of books issued per year for each student during their all-academic years.
-- Define the CTE expression name and column list.
WITH book_Issue_CTE (StudentID, StudentName, BookID, AcademicYear)
AS
(
-- Define the CTE query.
SELECT
BI.StudentID,
StudentName,
BookID,
YEAR(issueDate) AS AcademicYear
FROM
Tbl_Bookissued BI
JOIN
tbl_student s ON BI.StudentID = s.StudentID
WHERE
BI.StudentID IS NOT NULL
)
-- Define the outer query referencing the CTE name.
SELECT
StudentID,
StudentName,
COUNT(BookID) AS TotalBookIssued,
AcademicYear
FROM
book_Issue_CTE
GROUP BY
AcademicYear, StudentID, StudentName
ORDER BY
StudentID, AcademicYear;
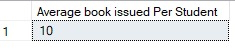
B. Use a common table expression to limit counts and report averages: The following example shows the average number of books issued for all years for the students.
WITH Avg_book_Issue_CTE (StudentID, NumberOfBooks) AS
(
SELECT StudentID, COUNT(*)
FROM Tbl_Bookissued
WHERE StudentID IS NOT NULL
GROUP BY StudentID
)
SELECT AVG(NumberOfBooks) AS "Average book issued Per Student"
FROM Avg_book_Issue_CTE;
C. Use multiple CTE definitions in a single query: The following example shows how to define more than one CTE in a single query. Notice that a comma is used to separate the CTE query definitions.
In the example below, we are fetching records of books issued to teachers and students.
WITH book_issued_student_CTE (StudentID, BookIssued, IssueYear) AS
-- Define the first CTE query.
(
SELECT StudentID, COUNT(BookID) AS BookIssued, YEAR(issueDate) AS IssueYear
FROM Tbl_Bookissued
WHERE StudentID IS NOT NULL
GROUP BY StudentID, YEAR(issueDate)
),
-- Define the second CTE query, which returns sales quota data by year for each sales person.
book_issued_Teacher_CTE (TeacherID, BookIssued, IssueYear) AS
(
SELECT TeacherID, COUNT(BookID) AS BookIssued, YEAR(issueDate) AS IssueYear
FROM Tbl_Bookissued
WHERE TeacherID IS NOT NULL
GROUP BY TeacherID, YEAR(issueDate)
)
-- Define the outer query by referencing columns from both CTEs.
SELECT CTE.StudentID,
StudentName,
NULL AS TeacherID,
'' AS TeacherName,
BookIssued,
IssueYear
FROM book_issued_student_CTE CTE
JOIN tbl_student s ON CTE.StudentID = s.StudentID
UNION ALL
SELECT '',
'',
CTE.TeacherID,
TeacherName,
BookIssued,
IssueYear
FROM book_issued_Teacher_CTE CTE
JOIN tbl_teacher t ON CTE.TeacherID = t.TeacherID
ORDER BY CTE.StudentID, TeacherID;
D. Use a recursive common table expression to display multiple levels of recursion: The following example shows managers and the employees reporting to them. The number of levels returned is limited to two.
Create one more table to proceed with this example.
-- Create an Employee table.
CREATE TABLE dbo.Employees
(
EmployeeID SMALLINT NOT NULL,
FirstName NVARCHAR(30) NOT NULL,
LastName NVARCHAR(40) NOT NULL,
Title NVARCHAR(50) NOT NULL,
DeptID SMALLINT NOT NULL,
ManagerID SMALLINT NULL,
CONSTRAINT PK_EmployeeID PRIMARY KEY CLUSTERED (EmployeeID ASC),
CONSTRAINT FK_Employees_ManagerID_EmployeeID
FOREIGN KEY (ManagerID) REFERENCES dbo.Employees (EmployeeID)
);
-- Populate the table with values.
INSERT INTO dbo.Employees
VALUES
(1, N'Ken', N'Sánchez', N'Chief Executive Officer', 16, NULL),
(273, N'Brian', N'Welcker', N'Vice President of Sales', 3, 1),
(274, N'Stephen', N'Jiang', N'North American Sales Manager', 3, 273),
(275, N'Michael', N'Blythe', N'Sales Representative', 3, 274),
(276, N'Linda', N'Mitchell', N'Sales Representative', 3, 274),
(285, N'Syed', N'Abbas', N'Pacific Sales Manager', 3, 273),
(286, N'Lynn', N'Tsoflias', N'Sales Representative', 3, 285),
(16, N'David', N'Bradley', N'Marketing Manager', 4, 273),
(23, N'Mary', N'Gibson', N'Marketing Specialist', 4, 16);
After running this script we have the following data.
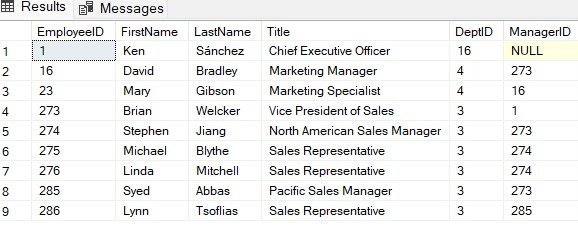
The following example shows the hierarchical list of managers and the employees who report to them.
WITH DirectReports(ManagerID, EmployeeID, Title, EmployeeLevel) AS
(
SELECT
ManagerID,
EmployeeID,
Title,
0 AS EmployeeLevel
FROM dbo.Employees
WHERE ManagerID IS NULL
UNION ALL
SELECT
e.ManagerID,
e.EmployeeID,
e.Title,
EmployeeLevel + 1
FROM dbo.Employees AS e
INNER JOIN DirectReports AS d
ON e.ManagerID = d.EmployeeID
)
SELECT
ManagerID,
EmployeeID,
Title,
EmployeeLevel
FROM DirectReports
ORDER BY ManagerID;
The output of this CTE will be.
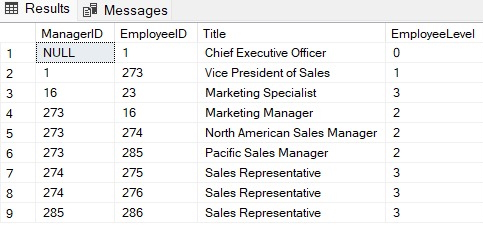
E. Use a recursive common table expression to display two levels of recursion: The following example shows managers and the employees reporting to them. The number of levels returned is limited to two.
WITH DirectReports (ManagerID, EmployeeID, Title, EmployeeLevel) AS
(
SELECT ManagerID, EmployeeID, Title, 0 AS EmployeeLevel
FROM dbo.Employees
WHERE ManagerID IS NULL
UNION ALL
SELECT e.ManagerID, e.EmployeeID, e.Title, EmployeeLevel + 1
FROM dbo.Employees AS e
INNER JOIN DirectReports AS d
ON e.ManagerID = d.EmployeeID
)
SELECT ManagerID, EmployeeID, Title, EmployeeLevel
FROM DirectReports
WHERE EmployeeLevel <= 2;
The result of this CTE will be.

HostForLIFEASP.NET SQL Server 2022 Hosting
